中國經濟與金融市場動態頻傳,兩大事件尤為引人矚目:一是憑借新興物流與科技平臺崛起的企業家,以‘搬運工’的實干形象再度登頂中國首富寶座,凸顯實體經濟與創新融合的力量;二是外資機構正加速在中國私募基金市場的備案登記步伐,彰顯中國金融開放持續深化,為全球資本帶來新機遇。社會經濟咨詢服務行業隨之蓬勃發展,成為連接政策、市場與投資者的重要紐帶。
首富更迭往往映射經濟趨勢。本次登頂的‘搬運工’代表,其企業從基礎物流拓展至供應鏈管理、數字科技等領域,通過高效整合資源,降低社會運行成本,創造了巨大價值。這不僅是個人財富的積累,更是中國制造業升級、內需市場壯大以及新基建賦能的縮影。在疫情后全球經濟復蘇的背景下,此類以效率和創新驅動的商業模式,正獲得資本市場的高度認可,也為就業與區域發展注入活力。
另一方面,金融開放政策效應持續顯現。隨著中國取消外資持股比例限制、簡化準入流程,多家國際知名資產管理公司近期密集完成私募基金管理人備案登記。這一趨勢表明,外資機構看好中國中長期經濟增長潛力,積極布局股票、債券及另類投資市場,以分享中國消費升級、產業轉型的紅利。加速備案登記有助于引入國際先進經驗,促進國內資管行業競爭與規范發展,同時為境內投資者提供更多元化的理財產品選擇。
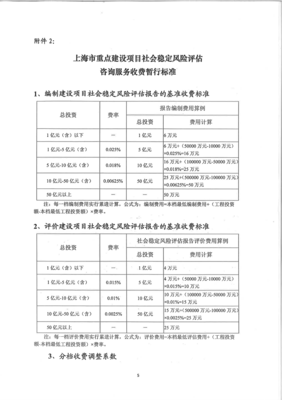
社會經濟咨詢服務作為配套產業,也隨之迎來增長契機。在復雜的經濟環境中,企業、政府及個人對政策解讀、市場分析、投資決策支持的需求日益上升。咨詢機構通過專業研究,幫助客戶把握外資流入動向、首富企業背后的產業邏輯,以及宏觀政策調整的影響,從而優化戰略布局。這一行業的壯大,提升了經濟運行的信息透明度與效率,有助于資源配置優化。
首富背后的產業動能與外資加速入場,將共同塑造中國經濟發展新圖景。實體經濟與金融開放雙輪驅動,配合專業咨詢服務支撐,有望增強經濟韌性,推動高質量發展。投資者與市場參與者需密切關注相關動態,以捕捉變革中的機遇。